發布日期:2022-10-09 點擊率:43
人工智能機器學習有關算法內容,請參見公眾號“科技優化生活”之前相關文章。人工智能之機器學習主要有三大類:1)分類;2)回歸;3)聚類。今天我們重點探討一下Apriori算法。 ^_^
Apriori算法是經典的挖掘頻繁項集和關聯規則的數據挖掘算法,也是十大經典機器學習算法之一。

Agrawal和Srikant兩位博士在1994年提出了Apriori算法,主要用于做快速的關聯規則分析。
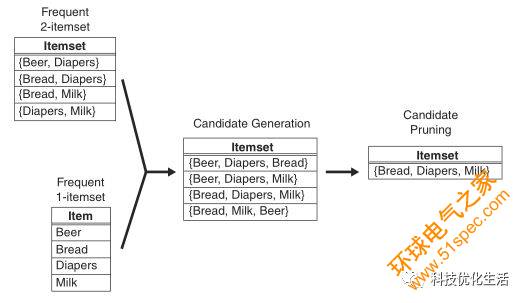
A priori在拉丁語中指"來自以前"。當定義問題時,通常會使用先驗知識或者假設,這被稱作"一個先驗"(a priori)。Apriori算法正是基于這樣的事實:算法使用頻繁項集性質的先驗性質,即頻繁項集的所有非空子集也一定是頻繁的。
Apriori算法概念:
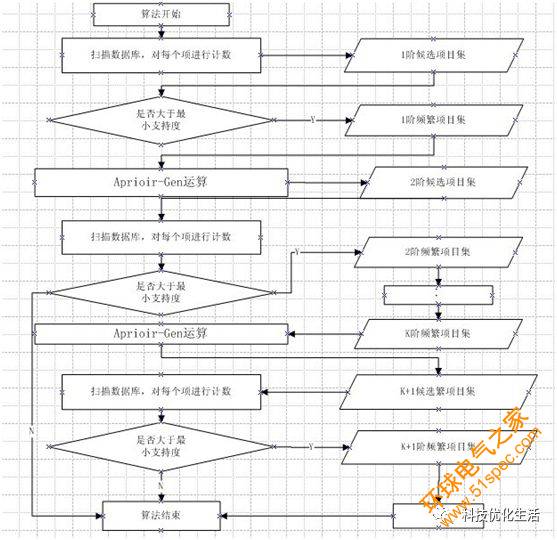
Apriori算法使用一種稱為逐層搜索的迭代方法,其中k項集用于探索(k+1)項集。首先,通過掃描數據庫,累計每個項的計數,并收集滿足最小支持度的項,找出頻繁1項集的集合。該集合記為L1。然后,使用L1找出頻繁2項集的集合L2,使用L2找出L3,如此下去,直到不能再找到頻繁k項集。每找出一個Lk需要一次數據庫的完整掃描。Apriori算法使用頻繁項集的先驗性質來壓縮搜索空間。
注:數據庫中的數據可以是結構化的,也可以是半結構化的,甚至還可以是分布在網絡上的異構型數據。
Apriori算法是一種最有影響的挖掘布爾關聯規則頻繁項集的算法。其核心是基于兩階段頻集思想的遞推算法。該關聯規則在分類上屬于單維、單層、布爾關聯規則。在這里,所有支持度大于最小支持度的項集稱為頻繁項集,簡稱頻集。
Apriori算法中術語:
1、項集和K-項集
令I={i1,i2,i3……id}是數據中所有項的集合,而T={t1,t2,t3….tN}是所有事務的集合,每個事務ti包含的項集都是I的子集。在關聯分析中,包含0個或多個項的集合稱為項集。如果一個項集包含K個項,則稱它為K-項集。空集是指不包含任何項的項集。
2、支持度計數
項集的一個重要性質是它的支持度計數,即包含特定項集的事務個數,數學上,項集X的支持度計數σ(X)可以表示為 :
σ(X)=|{ti|X?ti,ti∈T}|
其中,符號|*|表示集合中元素的個數。
3、關聯規則
關聯規則是形如X→Y的蘊含表達式,其中X和Y是不相交的項集,即X∩Y=空。
關聯規則的強度可以用它的支持度(support)和置信度(confidence)來度量。
支持度確定規則可以用于給定數據集的頻繁程度,而置信度確定Y在包含X的事務中出現的頻繁程度。
支持度(s)和置信度(c)這兩種度量的形式定義如下:
s(X→Y)=σ(X∪Y)/N
c(X→Y)=σ(X∪Y)/σ(X)
其中, σ(X∪Y)是(X∪Y)的支持度計數,N為事務總數,σ(X)是X的支持度計數。
對于靠譜的關聯規則,其支持度與置信度均應大于設定的閾值。那么,關聯分析問題即等價于:對給定的支持度閾值min_sup、置信度閾值min_conf,找出所有的滿足下列條件的關聯規則:
支持度>=min_sup
置信度>=min_conf
把支持度大于閾值的項集稱為頻繁項集(frequent itemset)。因此,關聯規則分析可分為下列兩個步驟:
1)生成頻繁項集F=X∪Y;
2)在頻繁項集F中,找出所有置信度大于最小置信度的關聯規則X->Y
Apriori算法思想:
1)找出所有的頻集,這些項集出現的頻繁性至少和預定義的最小支持度一樣。
2)由頻集產生強關聯規則,這些規則必須滿足最小支持度和最小可信度。
3)使用第1)步找到的頻集產生期望的規則,產生只包含集合的項的所有規則,其中每一條規則的右部只有一項,這里采用的是中規則的定義。
4)一旦這些規則被生成,那么只有那些大于用戶給定的最小可信度的規則才被留下來。為了生成所有頻集,使用了遞歸的方法。
Aprior算法程序如下:

Apriori算法優點:
1)使用先驗性質,大大提高了頻繁項集逐層產生的效率;
2)簡單易理解;
3)數據集要求低;
4)擴展性較好,可以并行計算。
Apriori算法缺點:
1) 可能產生大量的候選集;
2) 可能需要重復掃描整個數據庫,非常耗時。
Apriori算法改進:
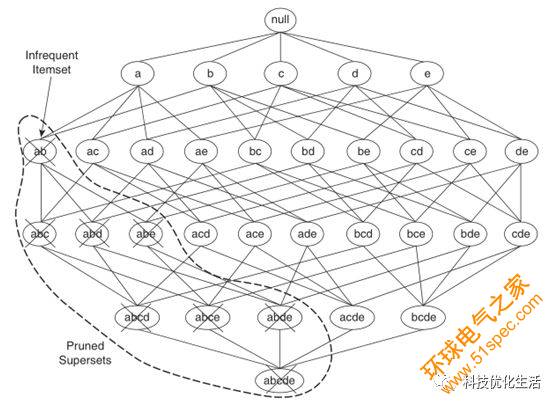
定理:如果規則X->Y?X 不滿足置信度閾值, 則對于X的子集X′->Y?X′也不滿足置信度閾值。
根據此定理,可對規則樹進行剪枝,其具體改進的算法如下:

Apriori算法應用:
通過對數據的關聯性進行了分析和挖掘,挖掘出的這些信息在決策制定過程中具有重要的參考價值。Apriori 算法被廣泛應用于各種領域:
1)應用于商業活動領域,應用于消費市場價格分析中,它能夠很快的求出各種產品之間的價格關系和它們之間的影響。
2)應用于網絡安全領域,通過模式的學習和訓練可以發現網絡用戶的異常行為模式,能夠快速的鎖定攻擊者,提高了基于關聯規則的入侵檢測系統的檢測性。
3)應用于高校管理中。隨著高校貧困生人數的不斷增加,學校管理部門資助工作難度也越加增大。針對這一現象,將關聯規則的Apriori算法應用到貧困助學體系中,挖掘出的規則也可以有效地輔助學校管理部門有針對性的開展貧困助學工作。
4)應用于移動通信領域。基于移動通信運營商正在建設的增值業務Web數據倉庫平臺,對來自移動增值業務方面的調查數據進行了相關的挖掘處理,從而獲得了關于用戶行為特征和需求的間接反映市場動態的有用信息,這些信息在指導運營商的業務運營和輔助業務提供商的決策制定等方面具有十分重要的參考價值。
結語:
Apriori算法是一種挖掘關聯規則的頻繁項集算法,其核心思想是通過候選集生成和情節的向下封閉檢測兩個階段來挖掘頻繁項集。主要用于做快速的關聯規則分析。Apriori算法在世界上廣為流傳,得到極大的關注。Apriori算法已經被廣泛的應用到商業、網絡安全、高校管理和移動通信等領域。
------以往文章推薦------
機器學習
深度學習
人工神經網絡
決策樹
隨機森林
強化學習
遷移學習
遺傳算法
樸素貝葉斯
支持向量機
蒙特卡羅方法
馬爾科夫模型
Hopfield神經網絡
回歸模型
K鄰近算法
卷積神經網絡
受限玻爾茲曼機
循環神經網絡
長短時記憶神經網絡
Adaboost算法
ID3算法
C4.5算法
CART算法
K-Means算法
下一篇: PLC、DCS、FCS三大控
上一篇: 索爾維全系列Solef?PV